
The Data Foundation and Workiva have teamed up to publish Transparent State and Local Financial Reporting: The Case for an Open Data CAFR.
The report explores why state and local Comprehensive Annual Financial Reports (CAFR) should be submitted and published as open data. The paper summarizes the steps necessary to create an infrastructure for open data CAFRs, addresses potential objections and challenges, and outlines the impact of currently-pending federal reforms.
The report recommends moving away from documents-based CAFR submissions and toward an open data submission.
Authors
Contents
Executive Summary
Dixon, Illinois, is widely known as the birthplace of Ronald Reagan, the fortieth president of the United States. But this small city is also home to what may be the greatest embezzlement scandal in the history of local government in the United States. In April 2012, Dixon comptroller Rita Crundwell was charged with stealing $53 million from city coffers over the course of 22 years.[1]
She had used the funds to build up a collection of 400 horses at the time of her arrest, far more than a public employee’s salary could possibly support. She had won numerous awards at national quarter horse competitions and been named the leading owner by the American Quarter Horse Association for eight consecutive years. Rita Crundwell pled guilty to her crimes, and she was sentenced to nearly 20 years in prison.[2]
There are many lessons for financial administration in the case of Rita Crundwell. The dominant one may be the importance of separating financial functions such as check processing and tax preparation from the audit process.[3] The accounting firm that provided all these services to Dixon paid $35 million to settle a claim that it should have discovered the embezzlement.[4]
But one detail in the story of Dixon reveals a way that future losses to state and local governments might be prevented. Local governments should make their financial information more transparent by publishing it as open data.
Sterling, Illinois, is a city near Dixon with a similar population and budget. In the spring of 2010, the city manager of Sterling noticed stark differences between the financial situations of the two cities: Sterling was in a good financial position, while Dixon was in arrears and borrowing. The city manager contacted a colleague in Dixon to ask questions. Unfortunately, these questions didn’t unearth Rita Crundwell’s financial fraud.[5]
But what if many more people had access to Dixon’s financial information because its reports were digitized in a machine-readable format, making the information easy to access, process, and analyze? What if there had been a simple way for software to draw comparisons between the financial status of Dixon and similar cities? What if it were easy for the state of Illinois, which oversees the finances of its local governments, to electronically compare municipalities that are of similar size, offer similar services, and have similar economies and demographics?
If Dixon’s reports had been encoded with machine-readable data, Rita Crundwell’s embezzlement may have been exposed much earlier. Maybe the higher risk of being caught would have prevented her from dipping into the city’s finances in the first place. By giving the state and others more visibility into municipal finances, open financial data could help suppress embezzlement of precious public funds.
State and local governments should modernize their public disclosures. Specifically, they should begin by publishing their Comprehensive Annual Financial Report (CAFR) as open data to create a more transparent and publicly accountable financial system, to discourage embezzlement and financial errors, and to learn more about their own financial status. The CAFR is a set of statements that comprise the financial report of a state, municipal, or other governmental entity. Unlike a budget, which sets out a plan for a future fiscal year and shows how tax revenue will be allocated, a CAFR contains the financial position of the jurisdiction that has resulted from prior years’ financial activities.[6] CAFRs comply with requirements promulgated by the Governmental Accounting Standards Board (GASB).
About 30,000 state and local governments in the United States, including the City of Dixon, produce audited financial statements each year. Not all jurisdictions publish CAFRs, but it is widely regarded as a financial best practice. Some publish a PAFR, or “Popular Annual Financial Report,” to make the extensive and highly detailed CAFR information more accessible to the general public—that is, to those without professional knowledge of government accounting and finance.[7]
The existence of PAFRs as interpretive aids to CAFRs invites more questions about potential benefits of open data: can open data simplify the preparation of and improve the trust in derivative reports? The answer to both is yes. In fact, the publication of the CAFR as open data would not only allow municipalities to easily transform their CAFRs into PAFRs, but it would also allow a wide variety of downstream users to more easily convert CAFR data into the type of reports that suit the many use cases our country and society society have for information about government finances, thereby improving transparency and oversight. No less importantly, municipal governments could use their own data to more easily fill out the myriad financial reports required by state and federal programs such as applications for federal grants, grant reports, and economic activity reports such as the F-28 to the US Census.
Among the most important uses of municipal financial data is its use by the municipal bond market to determine the price government entities pay to borrow funds for roads, schools, and other infrastructure construction and repair. If the municipal bond market had the information contained in CAFRs as open data, instead of just as old-fashioned documents, it would cost less for market participants to gauge the creditworthiness of towns and cities. New ways of slicing and dicing data—including the potential use of machine learning—might help them to discover better ways to separate good credit risks from bad. The result would be better borrowing terms for many government entities and the carrot of better terms for those that improve their financial reporting.
But what does publishing CAFR information as open data really mean? The information is already accessible on the pages of a CAFR document, and CAFRs are typically posted online as PDF (Portable Document Format) files. Isn’t that enough?
No—because information has meaning that is independent of the document in which it is published. Replacing document-based reporting with open data submissions would allow CAFR data to almost literally leap from the page. Open data can be searched and sorted, remixed and reprocessed, and put to new and better uses, both those we can imagine and those we cannot.
PDF documents are not good enough. The PDF electronic document standard merely tells computers how words and numbers should appear on a page. It does not describe what the words and numbers mean. An open data CAFR would enable the automated ingestion and meaning-full analysis of the data by computers with minimal or no human intervention.
“This process will change the manner in which state and local financial information is reported, but not its substance. An open data CAFR would not require state and local governments to report different information, but only to report the same information using different electronic packaging.”
The process of establishing the necessary infrastructure for an open data CAFR will require two basic steps:
First, participants in the municipal financial reporting ecosystem must get together and define an information model for the contents of CAFRs.
Second, they must settle on a data encoding language for implementing that information model.
These two steps will allow the contents of CAFRs to be published as machine-readable data. Thanks to the work of organizations like GASB and the Government Finance Officers Association, there is already a well-developed structure for the concepts of financial reporting, so the project of modeling that information will not require new ground to be broken. And there is a leading candidate for a data encoding language: XBRL, or eXtensible Business Reporting Language (See Part IV).
This process will change the manner in which state and local financial information is reported, but not its substance. An open data CAFR would not require state and local governments to report different information, but only to report the same information using different digital packaging.
There are certainly substantial impediments to the project of establishing this infrastructure, not the least of which is inertia. Most human beings don’t like change. Often, this resistance is based on a perception that the costs exceed the benefits. Other times, this resistance is strategic because the change simply cannot be accomplished by individual entities acting on their own. That’s why the transformation of CAFRs from documents into open data will require collaboration and leadership. The benefits accrue when a critical mass of entities embrace and use the same standards.
This report explains why state and local financial reports should be submitted and published as open data, rather than just as documents (Parts II and III); summarizes the necessary steps to create an infrastructure for open data CAFRs (Part IV); anticipates objections and challenges (Part V); and outlines the impact of currently-pending federal reforms (Part VI). To inform this report, we interviewed fourteen noteworthy leaders in state and local finance (see Appendix). We believe more careful study and coalition-building will be necessary to achieve a full transformation from documents to data. But we are confident that the essentials of the case for open data and the steps to bring it about are contained herein.
What’s Wrong With PDF? From Documents To Data
The introduction of digital documents, including the now-ubiquitous but still-proprietary PDF electronic document standard by Adobe Inc. in the 1990s, was a tremendous advance for the electronic availability of unstructured, document-based information. Before PDF, the best and most common way for people to disseminated financial and statistical information was to print it on paper and send that physical paper around, with all the costs, delays, and interpretive uncertainty that process entailed.
But the PDF is now old news. The state of the art in publication is swiftly shifting toward publication of the data that underlies documents.
“State and local governments reporting their financial information, and consumers of that information, do not have to choose between human-readability and machine-readability. New data encoding formats such as iXBRL expand the potential uses for financial information, limited only by the imaginations of downstream users.”
What was formerly presented only in a single, static way can now be presented in both a highly readable format for humans and also as data to be processed by computers. State and local governments reporting their financial information, and consumers of that information, do not have to choose between human-readability and computer-readability. New data encoding formats such as iXBRL; (explained below) expand the potential uses for these reports, limited only by the imaginations of downstream users. PDF and other static forms of publication are the way of the past.
Given the feasibility of open data, PDF publication of the CAFR imposes unnecessary costs on downstream users in two ways. First, if they want to use CAFR data in a comprehensive way, users must pay intermediaries to convert CAFRs into usable data. Data aggregators such as Bloomberg, S&P Global, Refinitiv (formerly the financial and risk business of Thomson Reuters), and others provide valuable insights. However, our society would enjoy many benefits if these intermediaries were able to ingest the data automatically, , thus, reducing the costs of their data-gathering services. An open data CAFR eliminates the costs to translate CAFRs into data, and both data users and municipalities alike would save money. CAFR data could be available immediately at publication rather than weeks or months later, after data-processing.
A second, related way that the static CAFR imposes costs is the limitation that it places on new and creative uses of CAFR data. It is a simple law of innovation that high costs reduce experimentation. Experiments have no guarantee of a return, so the demand for experimental uses of data drops off steeply in relation to price. If it cost less in dollars and mental energy to acquire high-quality CAFR data, new uses of the data would spring forth. We cannot know what those uses would be, but if barriers are lowered, new applications will emerge.
The fundamental shift from PDF documents into open data has already begun in the corporate sector and in federal finance. The federal government began requiring open data within corporate financial reporting a decade ago. In 2017, all federal agencies likewise began reporting their own financial information as open data (See “Federal Open Data Transformations,” below). These transformations offer a useful guide for the future of state and local finance.
Federal Open Data Transformations
“Open data” refers to information that is expressed in a machine-readable way and is freely available for public access. Over the last decade, U.S. federal policymakers have begun mandating open data for financial information reported by public corporations and by the agencies of the federal executive branch. When corporate and federal financial reports are expressed as open data, instead of as plain-text, or even PDF, documents, the information contained in them is more easily compiled and can be electronically analyzed without further translation.
In order to move from document-based reporting to open data reporting, an information model that captures the content to be reported and how information elements relate to one another must first be created. Second, a data encoding language, expressing the information in well-defined data fields, must be adopted.
Open data for corporate financial reporting. In 2009, the U.S. Securities and Exchange Commission began requiring issuers of corporate securities to report their financial statements as open data,[8] using an information model maintained by the Financial Accounting Standards Board (FASB).[9] The SEC publishes all such data online for free access by investors, markets, and the public.[10] The SEC's decision was part of a global trend. Nearly every major securities regulator in the world now requires the public companies in its jurisdiction to report financial information in XBRL. The SEC's information model has been criticized as poorly reflective of the meaning of underlying accounting standards, and its taxonomy has been criticized as overly complex.[11] Nevertheless, all major market data companies now use this corporate financial data to create products for investors,[12] and the SEC itself analyzes the data to find indicators of possible accounting fraud.[13]
Open data for federal agency financial reporting. In 2014, Congress enacted the Digital Accountability and Transparency Act (DATA Act), which requires all executive-branch agencies to report their spending information as open data.[14] Under the law, the Treasury Department and the White House Office of Management and Budget created an information model of the basic concepts of federal spending information and a taxonomy, known as the DATA Act Information Model Schema (DAIMS),[15] that expresses that spending information as data fields. In May 2017, every agency began reporting spending information to the Treasury Department as open data, submitting data files encoded using the DAIMS every quarter.[16] The Treasury Department publishes all such data online on its USASpending.gov portal.[17] The U.S. federal government’s adoption of an open data mandate for its agencies’ financial information has created new ways for Americans, their representatives in Congress, and the agencies themselves to understand and manage spending.[18]
Because state governments are sovereign, there can be no federal mandate for open data across all state and local financial reporting. However, two existing federal reporting systems—grant reporting and municipal securities reporting—already involve nearly every state and local government, because almost every state and local government entity receives federal grants, issues federally-regulated bonds, or both, and regularly submits a CAFR to fulfill the related reporting requirements. Congress is currently considering legislation that would create open data mandates in both of those existing federal reporting systems: the GREAT Act would apply to the grant reporting system, and the Financial Transparency Act would apply to the municipal securities reporting system. Together, the enactment of the GREAT Act and the Financial Transparency Act would create the necessary critical mass of entities preparing and filing open data CAFRs. Both are described in more detail in Part VI, below.
Even without the enactment of these two federal laws, the work of creating an infrastructure for open data for state and local financial reports can move forward through proactive cooperation between state and local governments and the organizations that represent them. The urgency for open data is strong, as PDF documents do not meet the needs of governments, markets, and constituents.
There are already many benefits to the uses of the financial information contained within CAFRs. It is not hard to imagine that the uses and benefits of that financial information will multiply when submitted and published as open data, instead of trapped within a static PDF.
The Benefits Of An Open Data CAFR
The benefits of an open data CAFR would be many. First, a primary, known benefit of an open data CAFR would be to energize and strengthen the municipal finance market, reducing the cost of government borrowing by improving liquidity.
In addition, if CAFRs were available as open data, the reduced costs for accessing and analyzing financial information would enable new applications that would support other public benefits, such as improved management, increased public confidence, and a stronger democracy. Some of these new or expanded uses of CAFR information are easy to predict.
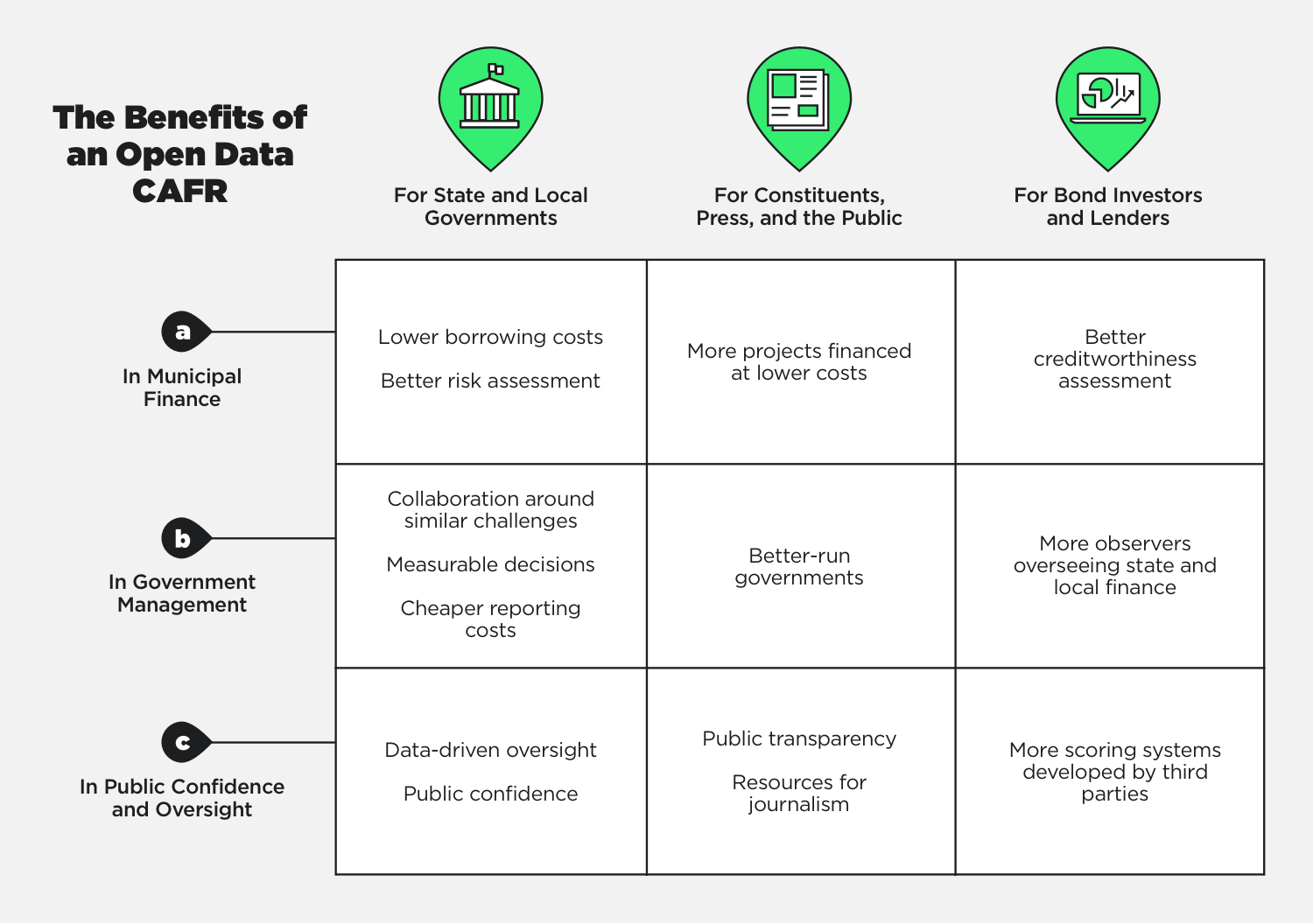
A. Municipal Finance
Among the most important uses of the CAFR is in the issuance and trading of municipal bonds. Just like businesses, government entities often require financing for projects, including roads, bridges, airports, utility systems, and so on. To finance such projects these government entities issue debt—that is, bonds that promise payment of a certain interest rate on loaned money as well as the principal balance at a given time.
Bonds are a financial tool that allows government entities to smooth out their revenues and expenses. With a bond issue, government entities can fund larger projects without a large tax increase and without waiting to save up a project nest-egg. Issuers of municipal bonds include states, cities, counties, redevelopment agencies, special-purpose districts, school districts, public utility districts, publicly owned airports, and seaports. In exchange for interest payments, investors in municipal bonds fund the costs of public projects to address challenges that range from traffic congestion to economic development to climate change—projects that improve the quality of life in communities and promote human flourishing.[19]
Just like businesses, government borrowers must offer to pay an interest rate that is attractive enough to get people to lend them money in light of the risk that they will default on payments. CAFR data is one of the principal ways that lenders assess the creditworthiness of local government entities.
Because CAFRs are currently published in PDF format, the data is not directly available to users on a timely basis. Because they lack resources to pore over thousands of CAFRs to retrieve the data they need, data users in the municipal bond market purchase the data from companies that specialize in converting the information in CAFRs into usable data. Publishing the data in a machine-readable format that data aggregators can automatically ingest will lower the cost of acquiring the data and make the data available more quickly. Having access to the data on a timelier basis will enable data users to do a more thorough assessment of credit risk, thereby enabling the market to divide the government entities that are good credit risks from the poor ones. This will have the knock-on effects of lowering the interest rates paid by governments who present good credit risks and motivating the governments who pose greater risk to improve, because improvement pays off with better interest rates.
In the current environment, it is harder to assess credit risk than it should be. In the words of one bond analyst, the municipal market is twenty years behind other asset classes. The natural result is that the interest rates many government entities pay are higher than they should be. The less investors are able to compare and analyze detailed data on municipal bonds, the more risk they perceive. The perception of higher risk leads them to demand higher interest rates or refuse to invest at all, contributing to illiquidity. A 2011 Brookings discussion paper estimated that market illiquidity adds more than 1.1% to municipal bond yields, suggesting over $30 billion in extra annual interest costs.[20] More data in more usable formats would flush some risks out of the municipal bond system and reduce the cost of borrowing overall. That would mean more government projects financed at lower costs, with all the public benefits, economic growth, and revenue growth that would result.
B. Management, Reporting, and Cost Control
Improved credit risk assessment and lower interest rates are not the only benefits of an open data CAFR. There are a variety of ways in which an open data CAFR can aid governmental entities in their own management, reporting, and cost-control.
As the story of Dixon, Illinois, illustrates, an open data CAFR could have valuable deterrence benefits for municipal management. That city, which lost over $50 million dollars to embezzlement, may have lost quite a bit less or nothing at all if there was a system by which a large number of observers could oversee municipal finances. An open data CAFR would facilitate such oversight, as well as more routine collaboration among diverse government entities, who could easily share and compare their financial information. Rather than communicating about common challenges with only the jurisdictions that are physically nearby, government managers might be able to find jurisdictions from across the nation with similar financial circumstances and challenges.
An open data CAFR would allow higher-level managers, such as state offices that oversee local finance, to identify which governments are struggling, the reasons why they are struggling (thanks to automated analysis built with machine learning), and which governments’ reserve funds are inadequate to the exigencies they are likely to face. The decisions that governmental entities have made would become more measurable if an open data CAFR were available to provide data for that use.
These benefits are already evident in federal finance, as federal agencies shift from document-based to open data financial reporting under the DATA Act, introduced above. Until the implementation of the DATA Act, federal agencies were in the same situation as state and local governmental entities are today: they compiled and generated document-based financial statements and reported those financial statements to the Treasury Department. They did not consistently report that information in any machine-readable way. But with the start of DATA Act reporting in May 2017, federal financial managers now have access to a unified open data set depicting all agencies’ spending, which facilitates cross-agency comparisons, automated antifraud reviews, and many other types of analyses.
Data found in the CAFR is used in myriad reports that government entities must file, such as grant reports sent to state or federal agencies that help fund their efforts. An open data CAFR would enable many of these reports to be generated quickly and easily, driving down the cost and operational burden of financial reporting for governmental entities. For example, a 2017 study of federal grant reporting by the White House Office of Management and Budget and the Department of Health and Human Services (HHS) found:
[T]wo of the main forms used for the annual audit that the federal government requires grantees receiving over $750,000 to complete, known as the Single Audit process, are duplicative ... HHS worked with other agencies to create an electronic environment in which grantees could report the information electronically, once, and fulfill the requirements of both forms ... “If grant recipients are able to eliminate duplicative input of [audit] information … they will have increased reporting accuracy and reduce the time it takes to [complete] their annual Single Audit.”[21]
By creating an open data CAFR, state and local governments can avoid duplicating their data entry tasks, saving time and reducing the errors that often crop up in duplicate spreadsheet reports. More importantly, they create a meaningful public data set that can be parsed and analyzed by many different stakeholders, including the public.
C. Public Confidence and Democratic Oversight
The idea of a PAFR—a Popular Annual Financial Report—suggests the public’s keen interest in overseeing their state and local governments’ finances. While the PAFR is a step in the direction of improved public oversight, an open data CAFR would significantly enhance and extend public oversight of government.
One of the primary actors in public oversight of government is, of course, the press. The “fourth branch of government,” or “fourth estate,”[22] pores over and popularizes details of governmental activity for the public to consume and react to. The Municipal Securities Rulemaking Board attests to the utility of the CAFR for such oversight, as it dedicates a page on its EMMA web site to a video introducing journalists to the CAFR.[23]
“EMMA” stands for “Electronic Municipal Market Access.” The web site does what its name suggests: providing information to the municipal bond market. The MSRB’s website is akin to the Securities and Exchange Commission’s EDGAR database, which provides open data on public companies (actual data encoded in XBR, not just PDF files) to investors, journalists, and the public.
A brief vignette illustrates how useful data can be. The MSRB debuted the EMMA site in 2008.[24] Almost immediately—in April of that year—a citizen journalist used data from the site to make a point about the finances of a small Tennessee city.[25] Whether the author of “Mt. Juliet doubled its debt in February, 2008” is correct about the condition of the city’s sewer fund is beside the point. What is clearly evident is that CAFR data is interesting to the public. Giving the public machine-readable data through an open data CAFR would improve consumption of the data and oversight of finances in governmental jurisdictions across the country.
This data is also useful to other constituencies. The Mercatus Center at George Mason University has a fiscal scoring system for states,[26] for example, that could be extended to smaller governmental units given the existence of open data from all the nation’s CAFRs. That system could readily inform the public of local government conditions and put local government leaders on notice when their own jurisdictions fall below national standards.
The USAfacts.org web site is another potential beneficiary. A project of former Microsoft executive Steve Ballmer, the site attempts to produce a “data-driven portrait of the American population, our government’s finances, and government’s impact on society.”[27] Its source of data for state and local government budgets, though, is the federal Census Bureau, and that data is current only as of 2014.[28] The benefits of timely analysis accrue when people and organizations can access CAFR data that is current, readily obtained, and adapted to the uses of projects like USAFacts.org. One can imagine, for example, a virtual assistant-type device that answers questions people have about their local governments as well as the local weather.
It is hard to quantify the potential benefits of the increased transparency that an open data CAFR could produce. However, an open data CAFR could help to improve public trust in local government and enhance democratic oversight. If there were well-structured and thoroughly vetted CAFRs, the public’s confidence in the administration of local government would certainly rise—perhaps, by small degrees in individual cases, but by a large degree in the aggregate.
Producing an open data CAFR system should be a priority. It would not necessarily be easy, but the benefits are significant enough to outweigh the challenges.
Building An Open Data CAFR
So what does it take to create an open data CAFR—that is, a publication that allows the information in a CAFR to leap from the page as data, available for republication, analysis, and reprocessing?
It is important to understand that transforming CAFRs from PDF documents into open data does not change their substance. In an open data world, state and local governments would report the same financial information, using the same categories and following the same accounting standards as before. All that would change is the packaging: CAFRs would be submitted and published as digital files, with each piece of information individually, digitally identified.
“An open data CAFR requires the creation of two key pieces of infrastructure. The first is a standardized semantic structure, or information model, to ensure that the same concepts are always expressed the same way. The second is a data encoding language that renders information in code so that it becomes machine-readable.”
A 2011 paper on government data transparency identified four interlinked publication practices that lead to transparency: authoritative sourcing, availability, machine-discoverability, and machine-readability.[30] CAFRs currently fail the fourth, and most important, publication practice: machine-readability. A transformation from PDF documents to open data will finally fulfill that fourth publication practice.
An open data CAFR requires the creation of two key pieces of infrastructure. The first is a standardized semantic structure, or information model, for the information. Each time a CAFR refers to “special assessment bonds,” for example, or “advance refunds” on existing bonds, it should refer to the exact same thing as all other CAFRs, and the relationships among such things should be clear. The second is the question of encoding the data: choices about how information conforming to an information model is rendered in a machine-readable syntax to be distributed far and wide.
These challenges are complex, and it may be oversimplifying to describe them as just two steps. But a lot of groundwork has already been laid for the publication of open data CAFRs.
A. Information Model
The first challenge in producing an open data CAFR is to capture all the relevant concepts in an information model.[31] All CAFRs must refer to the same things the same way, and the relationships among them must be clear, so that downstream data users understand what they are getting in the data, and so that they can be certain of comparing like to like: apples to apples, and oranges to oranges.
Happily, municipal finance is already a well-developed and organized field. Existing standards can, and should, form the basis of an information model.
The Government Accounting Standards Board (GASB) establishes accounting and financial reporting standards for U.S. state and local governments that follow Generally Accepted Accounting Principles (GAAP).[32] The Government Finance Officers Association (GFOA) helps to interpret the standards of the GASB. GFOA’s Governmental Accounting, Auditing, and Financial Reporting (“GAAFR” or “Blue Book”) is the “bible” that most governments use to classify their data.[33] These publications were originally created for accountants to read and use manually—not to serve as the basis for an information model. But the GASB and the GFOA have done a good job of developing common financial concepts that are now used throughout the state and local financial profession. These financial concepts can form the basis for an information model that will effectively distinguish different financial events and transactions.
An information model takes the disorganized world of human actions and interactions and imposes the kind of order that allows for processing of data about that world. The next step in the process is to determine the format in which to capture data about that now-more-ordered domain. That is the question of what data encoding language to use to capture the data.
B. Data Encoding Language
The second challenge is to express the information model using a data encoding language. A data encoding language puts the information into an electronic package that enables it to be easily exchanged, shared, and published.
A leading candidate for publication of the open data CAFR is eXtensible Business Reporting Language, or XBRL. XBRL is an offshoot of XML, or eXtensible Markup Language. And a refinement of XBRL called iXBRL may be well-suited for the open data CAFR. To understand the basic concept of this data encoding language, let us look at its parent: XML.
XML is a leading protocol for conveying digital documents and materials with which humans will interact. It uses “tags” surrounding text and other content to indicate how data will be presented. On web pages, the data-encoding language of HTML encloses text with a <b> opening-tag and a </b> closing-tag, indicating that the text should appear as bold when presented in a web browser. Since HTML, the markup language underlying the World Wide Web, is an XML-style protocol, it’s fair to say that XML is a foundational language of the World Wide Web. XML-style tags can also be used to convey meaning in a way that is amenable to computer processing. The XML tags surrounding the relevant piece of text use defined terms from the information model and unique identifiers to enable computer comprehension of published material.
For example, the following text tells a brief story about early American politics in a way that is XML-enhanced for computer processing. It relies on a system of tags with information about politicians, including a unique ID for political leaders:
When <name name-id="A000038">President <lastname>Adams</lastname></name> lost his reelection bid, he retired to Massachusetts.
This tells a computer that a person is being referred to by name. And because the name-id value "A000038" is presumed to be a unique identifier assigned to him, this tagging makes clear to a computer that the president named here is President John Adams, the second president of the United States, and not his son John Quincy Adams, the sixth president of the United States.
This type of tagging is also at work in XBRL, which was designed specifically for business and financial reporting. XBRL, maintained by a global consortium called XBRL International, “allows the creation of reusable, authoritative definitions, called taxonomies, that capture the meaning contained in all of the reporting terms used in a business report, as well as the relationships [such as arithmetical calculations] between all of the terms.”[34] Importantly, this means that XBRL not only presents the arithmetical relationships between terms, but it also automates the checking and validation of these relationships within a report.
For example, an XBRL taxonomy for the CAFR could specify that all of the revenue categories must add up to total revenue. This would allow every CAFR encoded in XBRL to be automatically checked for conformity to that requirement. A CAFR with a math or transcription error in one of the revenue categories would fail the check and could be automatically rejected and sent back for correction.
XML or XBRL for Financial Reporting: A Comparison
Standards create efficiency. When we agree on the width of train rails, an Internet-enabling protocol like TCP/IP, a markup language like HTML, or the financial reporting data encoding language called XBRL, we are enabling people and organizations to focus on the task at hand, rather than on resolving the distractions and struggles of incompatible means of communication.
EXtensible Business Reporting Language, or XBRL, is a derivative of eXtensible Markup Language, or XML, and it significantly extends the XML standard. These extensive additions are solely and uniquely well-suited for encoding financial reporting data. The demands of complex financial reports, like a CAFR, require commensurate capabilities in a data encoding language. Here we touch on some significant distinctions that recommend XBRL as best suited for financial reporting.
First, XBRL provides an extensive vocabulary to represent financial data “out of the box.” These include standard data elements for unit of measure, precision, and balance type (debit or credit). The XML standard does not provide for these "out-of-the-box” elements. With XML, such elements have to be newly agreed to and implemented with each new report, something that XBRL has already accomplished.
As their names suggest, both XML and XBRL are extensible;: that is, their respective vocabularies can be extended. This is how financial reports can be encoded: new data elements that represent a reporting entity’s unique or non-mandatory financial information can be added to the vocabulary for a particular report without creating any errors. This is the second significant distinction: only XBRL is uniquely capable of capturing how the new elements are connected to the existing ones.
As an example of these connections, XBRL allows software to validate whether the relationships between elements, as expressed within a particular report, follow established rules, or not. For example, if you have a standard element to represent cash and cash equivalents, as well as elements that represent types of liquidity, XBRL provides a way to specify that a fact tagged with the element "cash and cash equivalents" should not also be tagged as liquidity of type "noncurrent." While people in the financial reporting community know that cash and cash equivalents is a current asset, the XBRL taxonomy allows software to know this, and to reject financial statements that miscategorize cash and cash equivalents as a noncurrent asset.

These advantages of XBRL over XML are a result of XBRL’s use of taxonomies. In XBRL, a high-quality data dictionary, i.e., a “taxonomy” defines data elements without ambiguity, grounded in authoritative definitions. As noted above, an XBRL taxonomy can represent an information model, specifying how the terms in that vocabulary are permitted to overlap or intersect on a data value.
This leads us to a third advantage: XBRL validation software. XBRL validation software processes an XBRL taxonomy, validating its conformance to the XBRL standard. An XBRL validator also processes XBRL data files, validating both conformance with the XBRL standard and with the information model captured in a taxonomy.
A final, critical distinction is that with XBRL the taxonomy is stored separately from the data, while XML combines data and taxonomy into a single file. Thus, with XBRL, changes in accounting standards or other substantive rules can be accommodated by changing the taxonomy, adding data elements as needed. With XML, it is much more difficult to accommodate a new financial or accounting requirement; every piece of software must be updated. Keeping the open data standard current with financial reporting rules and practices is much easier when representing them in XBRL than in XML.
Because XBRL taxonomies capture the relationships between data elements, XBRL files can be validated without having any advance knowledge of how the data elements are supposed to add up. A software program checking on the arithmetic integrity of a CAFR encoded in XBRL would not need to understand that all revenue categories must add up to total revenue in order for a CAFR to be considered valid. That calculation could be specified separately, by the XBRL taxonomy. With regular XML, the software program would not be able validate a CAFR without having that calculation embedded in its own source code.
The highly-developed flexibility of XBRL, with definitions and meanings captured in a separate taxonomy, allows standard setters to make changes without forcing software providers to reprogram their source code. For instance, suppose the GASB decided to create a brand-new revenue category. With XBRL, that new revenue category could be reflected in a new version of the XBRL taxonomy. Software programs would refer to the updated XBRL taxonomy, automatically understand the new state of affairs, and include the brand-new category in their checks of each CAFR’s revenue line items. No changes to the software would be necessary. Not so with XML. In an XML world, every software program would have to be changed with every accounting standard change.
As mentioned above, the Securities and Exchange Commission requires public companies to report data in XBRL format so that it can be widely disseminated and processed.[35] The Federal Financial Institutions Examination Council uses XBRL-formatted data on banks.[36] Spain’s central government requires reporting in XBRL by 8,000 local governments.[37] XBRL is also used for various kinds of financial reports by dozens of other nations.
Inline XBRL (iXBRL) is a specialized version of XBRL that allows both machine-readability of financial data and the rendering of that data in a way that can be viewed on standard Internet browsers. Thanks to iXBRL, there should be no confusion between the data presented in a digital financial filing and the material that a person might read. One file presents the exact same information to both computers and humans.
There is already a working group dedicated to designing schemas and XBRL implementations for open data reporting of state and local government finances. The XBRL US State & Local Government Disclosure Modernization Working Group has the CAFR as one of several types of documents that it is working to modernize via open data publication.[38] The Working Group intends to create an XBRL taxonomy that is based on the underlying information model of GAAFR.
XBRL and its human-readable variant, iXBRL, do require more specialized tooling than simpler data encoding languages such as XML or the even simpler Comma Separated Values (CSV) format. The “Open Fiscal Data Package,” for example, touted by its advocates as “a simple, open, technical specification for publishing government budget and spending data,”[39] is used to create files in CSV that make financial information into machine-readable data. But this simplicity comes at a cost. As but one example of what is sacrificed, there is no way to automatically check the arithmetical relationship of financial line items in the Open Fiscal Data Package without already knowing how they are supposed to line up.
The appropriate stance is probably to practice a “measured embrace” of XBRL and iXBRL. This leading data encoding language for expressing financial data should be the first choice for the open data CAFR. Of course, technology evolves, and better-performing technology should always be considered as it becomes available and proven, and as the producers and consumers of state and local financial data become more sophisticated.
Finalizing an information model and coming to agreement on a data encoding language are substantial, but not insurmountable, tasks. They are at the heart of the project of moving to an open data CAFR. Once those challenges are overcome, there may be other impediments to surpass. They, too, can and should be overcome.
Impediments Of An Open Data CAFR
With all the benefits of an open data CAFR, one might expect the idea to be a matter of universal acclaim and rapid adoption. But this is not likely to be the case. The reasons are typical and understandable. The change to a new publication format involves a number of costs. Much can be done to reduce these costs or turn them into savings, and to demonstrate the net benefits.
Many governmental entities in the United States are small, and many have personnel handling financial matters who are part-time and self-taught rather than full-time, trained professionals. For these people and jurisdictions especially, the learning curve that must be traversed to produce an open data CAFR appears steep. Changing to a new publication format may seem daunting and time-consuming. Many may expect that shifting to open financial statements will result in increased expenditures of money, too, whether it goes for consultants, training, software, or what-have-you. Between difficult learning curves and increased costs, an open data CAFR may seem unattractive indeed.
Perhaps for this reason or others, the GASB’s “Electronic Financial Reporting” project appears to have petered out. Commenced in 2008, the project appears to be limited a decade later to merely monitoring developments in the area.[40] GASB’s “technical plan” for the second third of 2018 now relegates electronic financial reporting to the second-to-last page of the document.[41]
But CAFR producers should not be daunted by perceived costs. Part of the benefit of digital data processing is its scalability. It is well within the technical capabilities of software providers to build tools that the data producers in all small governmental entities can use to produce their own open data CAFRs. For example, open data advocate Marc Joffe has created an Excel spreadsheet that produces XBRL versions of the data in CAFRs.[42] Ideally, the open data CAFR project should be a net time- and cost-saver for small governmental jurisdictions.
After producing an information model and selecting a data encoding language, the third step in the open data CAFR project is for software providers to build the tools that make the publication of an open data CAFR extremely simple. There is no reason why the authors of CAFRs must understand and overcome all the technical challenges summarized above.
There are potential conflicts that may stand in the way of open data CAFRs, even if cost concerns can be allayed. In many instances, the firms that provide financial audits are the same firms that produce the CAFR. Some in the auditing community might be concerned that the efficiencies of an open data CAFR system would take away business. Unfortunately, the natural conservatism of the auditing community combined with that tinge of self-interest might cause auditors to try to stand in the way of progress on open financial data. However, there are many good reasons to push hard to overcome this type of inertia.
With standards of any kind, from railroad gauges to shipping containers to information models and data languages, there is a first-mover problem. The main benefits of open data CAFRs will only accrue when a critical mass of entities—state agencies, local governments, or both—begin submitting and publishing open data CAFRs. If just two or three municipalities were to publish open data CAFRs, the resulting data files would be interesting as proofs of concept, but there would be no incentive for software providers to create the analytics and reporting solutions that are needed for an entire ecosystem of state and local financial data to arise. Only when a critical mass of entities transform their CAFRs into open data will the needed solutions be built, thereby reducing bond rates, facilitating comparisons, creating public transparency, and delivering all the other benefits described above.
Reforms To Create A Critical Mass For An Open Data CAFR
As discussed above, there are impediments to digitizing the CAFR, including perceived potential costs and learning curves, particularly for smaller governmental entities. And those impediments are compounded by the first-mover problem that confounds any effort to create standards. What can be done about this?
In some cases, a national mandate to adopt open data is the solution. This is what happened in world of corporate finance. As described above, the Securities and Exchange Commission issued a rule requiring every public company to begin reporting its financial statements as open data, using XBRL.
However, under the Constitution, the federal government cannot simply mandate that all state and local governments begin submitting and publishing all CAFRs as open data. The background rule of constitutional federalism is that states are independent sovereigns whose functions cannot be commandeered by the federal government for its purposes.[43] That is for a good purposes: State policies produced at federal command make a hash of political accountability. Citizens have a very hard time discovering the politician to criticize or vote out of office when an ill-advised state law or regulation results from law or regulation at the federal level. What looks like a state policy is a federal policy that the state has been goaded into enforcing.
Moreover, in general, local governments are more responsive to voters and citizens than their larger and more remote counterparts. And having state and local jurisdictions experiment with diverse policies will produce natural experiments that all jurisdictions can learn from, resulting in a better-functioning polity overall.
Of course, there is no constitutional problem at all with a state government requiring its sub-units to produce open data CAFRs. The state of Florida has done exactly that in recent legislation. In March 2018, the governor of Florida approved H.B. 1073, which added language to the state’s taxation and finance code creating an “Open Financial Statement System.” The legislation requires the state’s Chief Financial Officer to commission “one or more eXtensible Business Reporting Language (XBRL) taxonomies suitable for state, county, municipal, and special district financial filings” and software “that enables financial statement filers to easily create XBRL documents consistent with such taxonomies.”[44] Though the legislation does not specifically require CAFRs to be filed in an open data format, it does say that if a suitable system exists, “all local governmental financial statements for fiscal years ending on or after September 1, 2022, must be filed in XBRL format and must meet the validation requirements of the relevant taxonomy.”[45] The precedent thus exists for states to mandate the modernization of financial reporting. In this case, Florida chose XBRL, and the project of producing open data financial reports is underway there.
If a state does not require itself and its sub-units to produce open data financial reports, a federal mandate might be needed, and there are good arguments to support a federal regulatory mandate. Congress and federal regulators have been very solicitous of state-federal relations in the area of municipal finance. Congress created the Municipal Securities Rulemaking Board in 1975—a “self-regulatory organization” acting under the Securities Exchange Commission—to help create a safe and fluid marketplace for municipal securities.[46] When it did so, it included language that protected municipal securities issuers from being subject to filing requirements issued by the MSRB or the SEC.[47] This language is colloquially referred to as the Tower Amendment for its author, Senator John Tower (R) of Texas.
But Congress could condition the receipt of grant funds on filing an open data CAFR. It could impose this condition on grant-receiving jurisdictions, or it could require any state receiving grant funds to require an open data CAFR of its sub-units.
This use of spending power—conditioning the receipt of federal funds on the following of federal mandates—has been approved by the Supreme Court.[48] In the case that did so, Congress conditioned the availability of highway funds on states adopting a minimum drinking age of 21 years. Pushing states to adopt substantive policies in exchange for federal dollars may seem a heavy-handed violation of the spirit of federalism. But a rule conditioning federal grant funds on filing uniform financial disclosures is narrow and quite germane to the grant-making process. This is ore relevant to us than the drinking age case for the federal government to use spending power authority to mandate an open data CAFR for those state and local government entities that receive federal grants.
This is the route taken by H.R. 4887, the Grant Reporting Efficiency and Agreements Transparency Act, or “GREAT Act.”[49] Introduced in January 2018, the bill has a section amending the Single Audit Act that would require grant recipients, including state and local government entities receiving grants, to submit financial statements, schedules of expenditures of federal grants, auditors’ reports, and other materials consistent with federal-government-wide open data standards. The House of Representatives passed the GREAT Act in September 2018, and further action is expected soon.
Another possibility is to direct the MSRB to set technological specifications for financial information submitted to EMMA. Since the MSRB was created by Congress under federal law, Congress has the authority to amend the law to require that CAFRs submitted to EMMA be expressed as open data.
This is the route taken by the Financial Transparency Act. Introduced in February 2017, the Financial Transparency Act directs all federal financial regulators to adopt open data requirements for all of the forms, filings, and other information they collect from the financial industry.[50] The bill specifically includes a section applying this general mandate to the MSRB, including the MSRB’s data collections via EMMA.[51]
Neither the GREAT Act nor the Financial Transparency Act is a direct mandate on state and local governments to produce open data CAFRs. They apply to specific activities that are already governed by federal law: receiving federal grants and underwriting or dealing in the national market in municipal bonds, respectively. The result of the enactment of the GREAT Act and the Financial Transparency Act would be to create an open data ecosystem for only those CAFRs that are prepared for grant compliance and municipal finance. Most state and local governments receive federal grants, issue bonds, or both, so the enactment of the GREAT Act and the Financial Transparency Act would likely create the critical mass of producers of open data CAFRs that is necessary to overcome the first-mover problem and other impediments.
Even in advance of legislative changes like the Financial Transparency Act, the MSRB’s long-range plan for the EMMA system says it will “expand the universe of information made available to the public through enhancements to existing document or data collections and through introduction of new categories of information. Such enhancements would be achieved through a combination of rulemaking and voluntary submission.”[52] That expanded universe of data would surely benefit the municipal securities market. It would also add to the management tools that state and local governments have at their disposal. And it would improve public oversight of government. Ultimately, progress will come from a combination of voluntary action by authorities like the MSRB, mandates from federal policymakers and states like Florida, and, most of all, collaborative leadership by the producers and consumers of state and local financial information.
Conclusion
On the outskirts of the world of CAFRs and public finance lurks a man named Walter Burien. Since at least 2001, Burien has maintained websites where he crusades against what he believes to be public scandals. He proclaims that CAFRs reveal massive deceit.
Every city, county, state, and the federal government keeps a virtually hidden, SECOND SET OF BOOKS which track the multi-TRILLION dollars in tangible wealth they have built up in these virtually hidden portfolios initially coming from investing YOUR skimmed tax money for over 50 years in everything from real estate to the stock market.[53]
Burien’s activism represents the antithesis of what people’s relationship to government financial reporting should be. Rather than an opportunity for accusations of scandal of epic proportions, CAFRs should be items of relatively common understanding and reference, and they should be a source of confidence. But Dixon’s CAFR—and the CAFRs of thousands of American towns with similar populations—are published as PDF documents, not machine-readable data files. There was no opportunity for analytical software to compare CAFRs and discover suspicious activity in Dixon's financial reports. Unfortunately, in the case of Rita Crundwell and Dixon, Illinois, Burien’s accusations would have been correct. Crundwell did succeed in skimming $53 million from Dixon taxpayers.
It is highly unlikely that “every city, county, state, and the federal government” has misappropriated its constituents’ tax money. But if bond investors, journalists, and citizens had access to the financial information contained in CAFRs as open data, future scams could be exposed and arrested, building confidence in the vast majority of honestly-operated governments.
Nobody could expect that every citizen and every bond investor would familiarize themselves with relevant CAFRs and their details, but a far greater number could, particularly because the software to do so has already been developed as a result of federal open data transformations. This is to be encouraged. The result of open data CAFRs would be Walter Buriens raising broad accusations, fewer Rita Crundwells justifying those accusations, and more citizens who are engaged and confident in what they know of their government’s finances.
Open data CAFRs would also improve management in state and local governments, which are always strapped for resources. An open data CAFR would be a valuable decision-making tool and a collaboration tool, not just for governmental entities that are geographically proximate to one another, but also for the national community of small government entities.
Producing the infrastructure for an open data CAFR is not necessarily easy. The groundwork has been laid, though, for an existing information model for governmental financial reporting. And leading data encoding languages are available in XBRL and iXBRL. Thanks to previous progress toward open data in corporate and federal financial reporting, the software tools needed to create open data CAFRs, once an information model and data encoding language are selected, already exist.
There are no technology barriers to prevent the movement to an open data model for governmental reporting. The only impediments to forward progress are human and institutional factors. The law of inertia applies not just to physical matter, but also to institutions and habits. Nevertheless, policymakers are pressing forward on open financial data, as Florida and the sponsors of the GREAT Act and the Financial Transparency Act have done. By whatever means it is adopted, now is the time to move to an open data transformation for state and local financial reporting.
Appendix
List of Interviewees
Gila Bronner, President and Chief Executive Officer, The Bronner Group
Rachel Carpenter, Chief Executive Officer, Intrinio
William D. Ferguson, City Accountant, City of Buffalo, New York
Joey French, Chief Financial Officer, Intrinio
Natalie Hanks, Florida Department of Financial Services
Marc Joffe, Senior Policy Analyst, The Reason Foundation
Ammiel Kamon, Chief Product Officer, OpenGov
Mike McCann, Vice President of Government Finance Solutions, OpenGov
Ernesto Lanza, Senior Counsel, Clark Hill
Lisa Morley, Product Manager, Tyler Technologies
Triet Nguyen, Managing Partner, Axios Advisors
Mark J. F. Schroeder, City Comptroller, City of Buffalo, New York
Shannon Sohl, Senior Research Associate, Center for Governmental Studies, Northern Illinois University
Claire Waldron, Special Assistant to the Comptroller, City of Buffalo, New York
A special thanks for Christina Scheuer for editorial assistance.

It was the discovery of a “secret” bank account by another Dixon city employee that started the unravelling of the scheme. ↩
Public Law 113-101 (May 9, 2014). ↩
See, e.g., Christopher Flavelle, Bloomberg, “Climate Change Will Get Worse. These Investors Are Betting On It” (Oct. 8, 2018, “’A storm surge barrier system protecting New York City and parts of New Jersey could cost $2.7 million per meter,’ Michael Cembalest, the asset manager’s chairman of market and investment strategy, wrote in his annual “Eye on the Market” energy newsletter in April”). ↩
See Hudson Hollister, Data Coalition, “White House’s DATA Act report: Standardized Data is Needed to Modernize Federal Grant Reporting – But Not Contract Reporting” (Aug. 16, 2017) https://www.datacoalition.org/white-houses-data-act-report-standardized-data-is-needed-to-modernize-federal-grant-reporting-and-but-not-contract-reporting/, citing White House Office of Management and Budget, Report to Congress: DATA Act Pilot Program (Aug. 10, 2017), https://www.whitehouse.gov/sites/whitehouse.gov/files/omb/sequestration_reports/2017_data_act_section5_report.pdf. ↩
Global Initiative for Fiscal Transparency, Open Fiscal Data Package web site, http://www.fiscaltransparency.net/ofdp/ (accessed Nov. 28, 2018); see also Frictionless Data, Fiscal Data Package web page, https://frictionlessdata.io/specs/fiscal-data-package/ (accessed Nov. 28, 2018). ↩
See New York .v United States, 505 U.S. 144, 175-76 (1992). ↩
§ 218.32(h), Fla. Stat. ↩
§ 218.32(h)(4), Fla. Stat. ↩
Pub. L. No. 94-29, §13. ↩
Section 15B(d)(1) of the Exchange Act provides: “Neither the Commission nor the Board is authorized under this title, by rule or regulation, to require any issuer of municipal securities, directly or indirectly through a purchaser or prospective purchaser of securities from the issuer, to file with the Commission or the Board prior to the sale of such securities by the issuer any application, report, or document in connection with the issuance, sale, or distribution of such securities.” ↩
South Dakota v. Dole, 483 U.S. 203 (1987). ↩
GREAT Act, H.R. 4887 (115th Cong., 1st Sess.) ↩
Financial Transparency Act, H.R. 1530 (115th Cong., 1st Sess.) ↩
Id. at Section 203. ↩
See Walter J. Burien, “Comprehensive Annual Financial Reports: The Biggest Theft In This World's History” https://web.archive.org/web/20010613235331/http://members.aol.com:80/_ht_a/cafr1/CAFR.html (accessed Nov. 28, 2018); see also http://cafr1.com/ (accessed Nov. 28, 2018). ↩
Revision Edition 3-20-19